MySBDS - Steem Blockchain Data Service in MySQL
MySBDS - Steem Blockchain Data Service in MySQL
What is the project about?
The Steem Blockchain Data Service is an open source project managed by Steemit that allows you to read the Steem blockchain and store it in a local MySQL database. The project opens with an obvious Notice:
This is prerelease software, not yet suitable for production use. Proceed at your own risk.
I'm working under this warning to get SBDS operational in the most stable way possible today, while watching and supporting the project as it moves forward. At this point, I've spent 100 hours (that I tracked, so more really) digging into SBDS and working to understand it. I'm not gonna give myself the Complete Understanding Badge yet, but I'm on my way.
MySBDS.com
Today, MySBDS.com and blervin/mysbds exist to provide three key things:
- Proven deployment scripts to get up and running with SBDS quickly
- Documentation of the challenges identified thus far (both on Steemit.com) and on MySBDS.com
- A public endpoint offering an always up-to-date full
mysqldumpof the entire Steem blockchain
I've dumped a pretty significant amount of time and energy into SBDS and I'm barely scratching the surface so I want to share everything I've found (today and ongoing) to get a dialog going with everyone else who's looking to get a local MySQL database running. And also to provide this public documentation of implementation results for the team working on updating the code for steemit/sbds.
My near-term goal is to get a public instance up and running for those who aren't quite ready to deploy and manage an entire environment themselves, but still wanna dig into the blockchain data.
Technology Stack
Everything outlined here is deployed in docker on CentOS 7.4 using common bash commands.
I will specifically outline a DigitalOcean deployment along with some useful functionality available there.
From what I see around here, it looks like Ubuntu is pretty popular so I'm planning to put together another version for that as well.
Roadmap
In order of complexity (and likely implementation):
- Prepare MySBDS.com to highlight current scripts, documentation, and the most relevant Steemit posts about SBDS
- Develop an Ubuntu deployment script
- Document and outline challenges with deployments
- Document my monitoring infrastructure
- Deploy a public MySQL server
- Explore interest in fully managed deployments or even replication
- Continue performance monitoring to identify refinements and share those insights
How to contribute?
Comment here and any other posts about SBDS, catch me on steemit.chat, or just let me know how you can help make the blockchain easily accessible in MySQL!
Deploy MySBDS
Overview
I was excited to play with the SteemSQL service that was originally public, so when it recently became a paid service a little beyond my budget I began to look for alternatives and I realized I could easily maintain my own copy of the blockchain.
At the time of this writing, the size of the MySQL database of the entire blockchain is 403GB, and growing rapidly. Because of this growth, I wanted to look at ways to deploy this on flexible infrastructure and I found a solution with Block Storage at DigitalOcean. This allows us to deploy storage at any size for $0.10/GB per month and increase that size at any time later, however, storage can never be decreased.
We'll walk through the steps to create a script that will deploy a cloud server at DigitalOcean running the Steem Blockchain Data Service and MySQL in docker.
Requirements
You will need an account at DigitalOcean to deploy a cloud server and related storage. Also, it is presumed that you are comfortable in the shell and understand how to connect to the server via SSH and perform basic systems admin work on a Linux platform.
Initial Setup
We need to ensure we deploy our droplet in a region that supports block storage. The supported regions for volumes are:
- NYC1
- NYC3
- SFO2
- FRA1
- SGP1
- TOR1
- BLR1
- LON1
- AMS3
You'll need to consider the size of the droplet you want to deploy, or the real question, whether you want to download the full mysqldump of the blockchain. I have written the low_mem.sh and high_mem.sh for both scenarios.
If you want to just get an instance up and slowly download everything, you can deploy a droplet with 4GB of memory and use the low_mem.sh script.
To download and restore the entire blockchain takes a fair amount of resources so the high_mem.sh script is written for 16GB of memory.
I'd give an estimate for times, but in my testing it varies a great deal depending on a lot of factors, including the node we're connecting to grab blocks. In general, it is always many hours but with the low_mem.sh deployment it may easily become a few days before it completes.
Prepare Script
Start by opening your favorite text editor such as Sublime Text or just Notepad and grab either the high_mem.sh or low_mem.sh script.
The first modification is to change the mysql_password in your copy of the script. Make that change and save your copy of the script. We'll modify this a bit more shortly.
mysql_password="mystrongcomplexpassword"
Create Droplet and Volume
We start by clicking the Create button and selecting Droplets

Then, we select CentOS and 7.4 x64 from the drop-down:
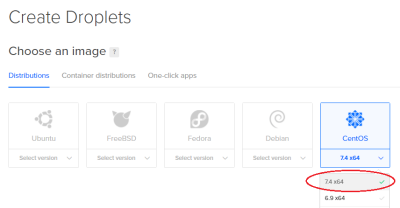
As we look to Choose a size you'll notice there are Standard Droplets and Optimized Droplets available. We can later expand our instance, however that expansion is only within this droplet type. You cannot deploy a Standard and later convert it to an Optimized instance, or vice versa.
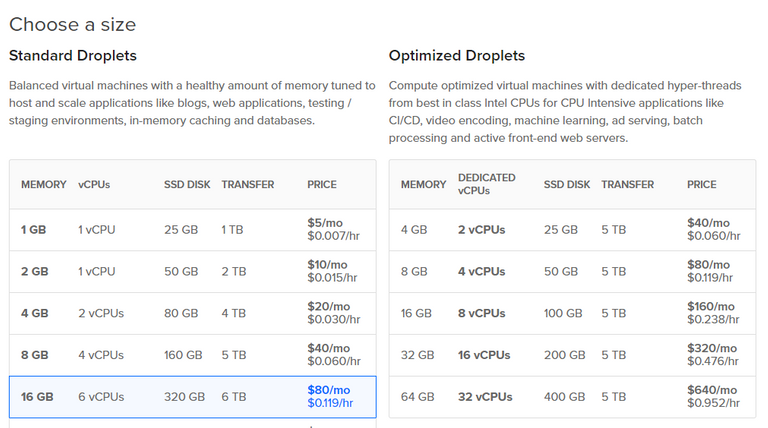
Next, click Add Volume to add block storage.

Given the current size of the Steem blockchain, I recommend using at least 500GB, especially if you plan to download the blockchain as you'll need the extra space.
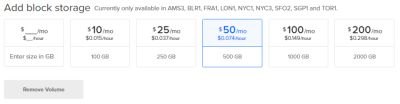
Next, we'll pick a region.

As you'll see, only the supported regions are selectable with all others grayed out.
Everything here around the volume name presumes a lot and those presumptions may be wrong. By default, DigitalOcean names a Volume as volume-{region}-{volume_index} where the index is essentially the count of Volumes you have in that region. Our approach here works in most scenarios, but if you have issues mounting your volume just look to the actual name displayed in DigitalOcean once it is created.
That said, we look to the following line in our script setting the volume_name variable:
volume_name="volume-tor1-01"
There are two parts to this name, the region (tor1 here) and the index of the volume (01 in this case) for that region.
If you do not have any volumes in the region you are using, this should deploy with the 01 index. If you have existing volumes in that region, it will increment to the next number. Update the volume_name accordingly.
Next, we check the User data box and paste in our modified script:
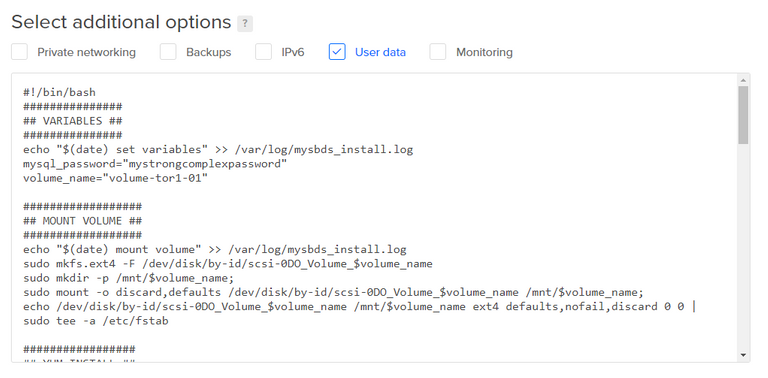
Now, we can scroll down and click the Create button.
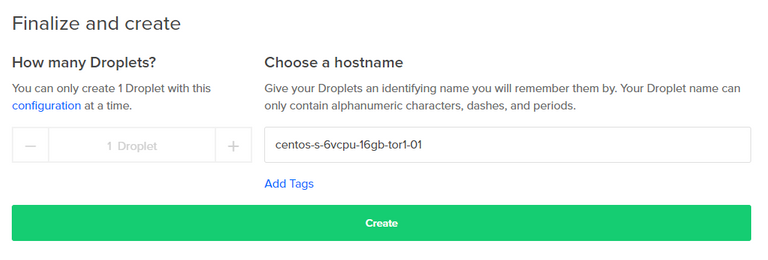
The page will refresh and bring us back to the list of droplets and you'll see this one building. Once it's complete, the IP address will appear and you can click the Copy link to grab that and paste into your SSH client such as Putty.
Known Issues
One thing I discovered quickly is that some of the sizes set for database fields are too small and we will see Data too long for column 'raw' errors.
Fortunately, the community stepped in and there is a pull request at github that fixes everything. My scripts here manually checkout that pull request rather than the master branch.
I know, I saw the signs that advised against hiking off-trail, but c'mon, this is an adventure so let's explore and see what we find! Dry humor aside, this branch has proven reliable in my testing so I'm comfortable with it but please advise of any issues you encounter.
The SBDS project still references steemd.steemit.com as the RPC node it connects to, but this was discontinued on January 6, 2018 so I've got a little sed in here to update that to api.steemit.com
Confirm Script Execution
The deploy will take a few minutes and you should check for the install email from DigitalOcean to get the password. Once you are logged in, check the script execution status by tailing the log we created.
tail -fn5 /var/log/mysbds_install.log
Somewhere between a few hours and a few days, you'll finally see:
END install
A simple way to check progress
mysql_ip=`docker inspect --format "{{ .NetworkSettings.IPAddress }}" steem_mysql`
mysql -h $mysql_ip -p -e "SELECT max(block_num) AS lastblock FROM sbds_core_blocks" steem
And you'll see something like this, with a much smaller block number.
+-----------+
| lastblock |
+-----------+
| 20065928 |
+-----------+
Then, just sit back patiently until everything fully syncs up.
You can watch the head_block_number shown at https://api.steemjs.com/getDynamicGlobalProperties to see how far along you are.
Conclusion
I plan to continue working with SBDS and updating this project with new scripts, tricks, and tools that I discover along the way.
I'm not seeing a whole lot of posts about SBDS so I'm hoping to open the discussion so we can all work together to get this running well. If you're already using SBDS or I just opened this door for you please comment and share your experiences! I'm gonna document everything I personally discover as well as any insights shared by the community.
My goal is to make it as simple as possible to push the blockchain to a MySQL database and I feel like I'm off to a good start.
Posted on Utopian.io - Rewarding Open Source Contributors
You got a 3.45% upvote from @ipromote courtesy of @blervin!
If you believe this post is spam or abuse, please report it to our Discord #abuse channel.
If you want to support our Curation Digest or our Spam & Abuse prevention efforts, please vote @themarkymark as witness.
You got a 15.38% upvote from @mercurybot courtesy of @blervin!
You got a 4.62% upvote from @upmewhale courtesy of @blervin!
You got a 6.06% upvote from @upmyvote courtesy of @blervin!
If you believe this post is spam or abuse, please report it to our Discord #abuse channel.
If you want to support our Curation Digest or our Spam & Abuse prevention efforts, please vote @themarkymark as witness.
You got a 2.01% upvote from @buildawhale courtesy of @blervin!
If you believe this post is spam or abuse, please report it to our Discord #abuse channel.
If you want to support our Curation Digest or our Spam & Abuse prevention efforts, please vote @themarkymark as witness.
This post has received a 5.08 % upvote from @boomerang thanks to: @blervin
Your contribution cannot be approved because it does not follow Utopian Rules
Hello, thanks for your post, however, we believe the SBDS is open source and your contribution is two scripts (configuration).
You can contact us on Discord.
[utopian-moderator]
Thanks for putting this information together. I've been wanting to get the steem blockchain in mysql for quite a while, and I've got a droplet on digitalocean running your script as I type. I'll be sure to let you know how it goes, but I might not be able to experiment with things again until tomorrow night. I just wanted to quickly say thanks.
Awesome, please follow up and let me know how it goes!
I'm currently on the step "build/run sdbs" and I see the mount is using 437G of space so things seem to be working. I'm having trouble finding out how to access the data in mysql, and I've tried setting up phpmyadmin, but I can only get phpmyadmin working on localhost and I can't seem to get it to working using the network ip. What program are you using the access the mysql data?
Here's a reliable tool you can use to connect: https://www.heidisql.com/download.php
I'm trying to find a way to connect to it using the same droplet on digitalocean. Maybe the problem is that I installed mysql on the droplet to be able to run phpmyadmin. For example, when I type the following command "mysql -u root -p" I can login with nothing as a password and then at the mysql prompt I can type "show databases;" and the only databases shown are information_schema, mysql, and performance_schema, and there is no reference to the steem mysql database. When I vi to /etc/my.cnf I see that the current data directory is "/var/lib/mysql" but I think the data your script generated is found in "/mnt/volume-tor1-01/volumes". I'll try to play around with it more later tonight. My goal is to be able to connect to the steem mysql data with php because that is the language I am most familiar with.
Yeah, installing mysql locally is fine, but might make it a little confusing since you now have two separate mysql instances running, but this should clarify.
To connect from the droplet itself, we need to look to the docker networking to find the IP the mysql container is running at by running this command:
For example, I get 172.17.0.2 as the IP. Then, you can connect using the IP returned from that command:
If you are connecting from any remote system, you can just use the public IP of this droplet with the normal port 3306.
Thanks for all your help. Since the commands you provided didn't work with my dual-mysql-trying-to-get-phpmyadmin-to-work setup, I destroyed the droplet I had been working on started over (I had to start over more than once because I forgot to increment the volume_name but thanks for your note about incrementing the volume name), and now it seems to be working for me like it is for you. I'm pretty excited because it looks like the hurdles have been removed so I can play around with the steem blockchain in mysql. Note: I tried using steemsql.com a while back but I wasn't able to get that to work with php in linux. Also, with the help of @eonwarped simplifying some Github instructions and pasting some commands for me I was able to get a condenser working which was neat to see, but my main motivation with setting up the condenser was because thought I would enable me to have the steem blockchain in mysql, but I couldn't get mysql working with the condenser, and when I saw the size of the condenser installation I doubted if it had all the blockchain data anyway. In short, I really appreciate there work you did here.
Sorry you had to start over but I'm glad you're up and running again. The learning curve here is a little steep but I've ran into most of the problems you'll see so don't hesitate to follow up if you have any other issues.
I'm running into an issue on my fresh install. The command "mysql -h 172.17.0.2 -u root -p" used to work for me during the download or restore phase, but now that I am in the "build/run sdbs" phase, that same mysql command produces the error, "ERROR 2003 (HY000): Can't connect to MySQL server on '172.17.0.2' (113)". I also tried connecting to the database remotely using the droplet IP (instead of 172.17.0.2), and I got a similar error except it mentioned (111) instead of (113). Do I just need to wait for the install script to finish or is there something else I need to do?
Check docker to make sure mysql is running:
If not, you can try starting it again:
And if you're still having troubles, you can take a look at logs:
This assumes you used the name
steem_mysqlas specified in my script, change as necessary.Thanks for helping me with the basics of docker. The "docker ps" showed that steem_mysql wasn't running so I ran "docker start steem_mysql" and then I saw that it was running, but I still couldn't connect so I ran the "docker logs steem_mysql" command and noticed a bunch of recent messages about doing a recovery, but the recovery seemed to finish in about three minutes and after that everything seems to work as expected :)
Awesome, glad you got it going!
This all underscores how many 'grey areas' I left ambiguous in here, so I'm putting together a more thorough tutorial that'll go into docker and other details a bit more.
Sorry to keep troubling you. I'm noticing that steem_mysql keeps stopping and gives the following type of error, "Aborted connection 5 to db: 'steem' user: 'root' host: '172.17.0.3' (Got an error reading communication packets)". I keep restarting steem_myslq (I've restarted at least 10 times and probably closer to 20 times) and it was stuck on the lastblock of 20080434 for a long time, and then I checked again and and the lastblock jumped to 20192434. Is having to restart steem_mysql this many times normal?
No worries, it's good to document these issues in the blockchain so others can learn too!
Interestingly, this is one issue I have not yet run into. For me,
steem_mysqlhas been running flawlessly, it's thesteem_sbdscontainer that has stopped and had issues so far.My general thoughts are this may be system level issues. How much memory do you have? I've tested this in a 4GB instance and can say it definitely does NOT work with less, at least not reliably.
Also, you mentioned installing other tools so these may also have an impact.
Something to check is to dump all the logs to local files so you can parse and review more easily. Docker makes it a little weird, so use this technique:
I didn't install any other tools in this particular setup (I destroyed the server with the other tools), and I think I adhered very closely to the instructions you provided. I'm using the 16GB digitalocean server and 500GB volume that were recommended in the instructions, and I used the high memory script.
Alright, with that deploy when you're doing the database restore, that does hammer
mysqlpretty hard so that's probably the main issue here.Again, check the docker logs to see if anything obvious pops out there. Beyond that, watch
mysqlto see what it's doing by running this command:While the restore is running, you should see 'INSERT INTO...' in the process list for many hours.
If
mysqldies, you shouldn't need to start all the way over. Assuming that you still have all the .gz files in the dump/ folder you can run this:Obviously, update the password and volume. This is just part of the script that calls the import.
I haven't been too suspicious about the database restores because I actually did the restores twice (onec on the server I destroyed and once on the current server), and both times seemed to take about the same amount of time (maybe around 8 hours) and both resulted in about the same amount of space being used on /mnt so before investigating the database restore, I wanted to try something based on what you said about how you had no issues with steem_mysql stopping and that you tested things on 4GB so I'm in the process of trying things with your low memory script's mysql settings. More specifically, I removed both the docker steem_mysql and steem_sbds and then ran lines 38 and 59 in your low memory script to get them both going again, and I found I also had to rename a directory with a really long name that was in the "volumes" directory so the system would continue using all existing mysql data instead of populating mysql from scratch. So far things seem to be working as steem_mysql hasn't stopped in over an hour.
I'm glad it's coming together! It really is a lot of learning little pieces of the puzzle like this to understand everything. I'm still getting that tutorial together to walk through all of the steps like this in a little more detail.
One tip, renaming the volume could cause issues with docker (thought it sounds like it worked here) so here's a trick in case it comes up again.
Inside the volume folder you'll see another folder named
_datacontaining all of the databases. Make sure youdocker stop steem_mysqlfirst so nothing is running and then just move your_datafolder with all the existing data to overwrite the_datafolder in the running container. You can't just replace thesteem/folder as this is innoDB and needs theib...files as well.Then, just
docker start steem_mysqland it'll see the database.It still seems to be working, and the lastblock seems to stay very close to the current head_block_number.
Thanks for the tip about the _data folder. I was definitely not confident about what I did, but it is good to know the proper way to do things going forward.
Note: What I did fortunately had the same effect as overwriting the data folder in the running container because there was /old64characterdirectory/_data/ and /new64characterdirectory/_data/ and since I saw that the old one was about 360G but that only the new one was the only one being written to so I stopped both steem_mysql and steem_sbds and then removed the new one and renamed the old one to what the new one was which was a roundabout way of overwriting the _data folder in the running container, but my approach could have been problematic if there was anything other than the _data folder in the running container.
Awesome! To test, I run this a least once a day:
And check against the
head_block_numberhere: https://api.steemjs.com/getDynamicGlobalPropertiesI have fallen a bit behind a few times and as far as I can tell it's the public node we're connecting to that's the issue. Even so, stopping and restarting
steem_sbdsshould get you back on track eventually if you see you're falling behind.Yes, I've been checking the max block_num against the head_block_number throughout the day, and for the past 24 hours it seems to be keeping up well with about a 20 block lag which seems reasonable.
As a test I reverted back to the high memory settings (line 38 of your high memory script) to see if steem_mysql would keep stopping like it was doing before, and so far it has been working well for the past hour, and I plan to continue testing it out tomorrow to see if I need to do any restarts. I'm thinking that the high memory settings may only run into issues when it is way way behind on the block_num because maybe the high memory mysql settings cause the system to try and catch up too fast. It will be interesting to see if steem_mysql has any stops tomorrow.
I've pretty consistently stayed within 20 blocks as well, which is one minute and more than reasonable.
You're exactly right, the settings you changed are exactly what to tweak. I've been working on a new 'tutorial' post the past couple of days after gleaning a bunch of insights from our discussion.
I'm gonna put something together that goes through each piece of my scripts in more detail, including these mysql settings.
The high memory settings stopped working around noon today so it made it through the last night and and this morning and then failed. I started things up again tonight and noticed the server load go up to 18 in about 10 or 15 minutes with kswapd0 being the top process which I think is related to virtual memory.
I briefly looked for a way to change the mysql settings in docker without having to do the thing where I do a docker stop, rm, run, but I couldn't find a way.
At some point tomorrow I plan to go back to the low memory settings to see if they continue to work as well as they did yesterday.
This is good to hear. I only ran the high memory instance for a couple of days. I thought I had proved it enough, but obviously there's more to learn there.
As far as changing mysql settings in docker, I can see the settings with
docker inspectbut cannot find a way to set them.I was wondering about the possibility of zipping and tarring up the _data directory to populate sbds instead of using mysqldumps. For example, instead of just offering latest.tar for download on your website, would it also work to offer latest_data.tar as a download? There is probably a reason why mysqldumps are what people typically do, but I'm wondering if this is a special case where the _data directory might be a faster solution because the database restore took around 8 hours on a 6 virtual core machine with 16GB and the approach of downloading overwriting the _data directory could be much faster.
Haha, the
.tardownload itself was a whole other battle for me.The short answer is the
ibdata...andib_logfile...files are required as well as thesteem/folder, but those files contain data about all the databases on that server. Even so, this approach should work if you backup the entire_datafolder, but nothing short of that. That would almost assuredly go faster than dealing with the dump.Creating my
.taris no walk in the park either. I'm looping through the tables and doing amysqldumpone at a time and appending each of them to the.tarfile. This database is so huge a standardmysqldumpof the entire thing never finished once in my testing.It is difficult and expensive to be working with such large databases which got me thinking about a way to potentially reduce the size of the database by more than 50% without too much of a sacrifice. Anyway, I noticed that the sbds_core_blocks table accounts for around two-thirds of the entire database size, and I'm guessing that the mediumtext entry named, "raw" (probably for raw blockchain data) probably accounts for the vast majority of that space, and it got me wondering if it might be possible to simply replace the "raw" entries with a single character or something save space. For example, I think doing this might enable the entire database to fit comfortably on a single $40/month droplet with room to spare.
I've been asking myself this exact same question as well, your approach just may work. I'll definitely post if I find some answers.
Another thing that may be worth considering is that the comments table is the second biggest in storage space, and it may be worthwhile to save space removing removing older edited versions of the "body" mediumtext entries. For example, sometimes I edit a big long post a few times to correct a few typos and this type of editing may be fairly common and may be able to reduce the database size a lot.
Yeah, great point! The
bodyis fully duplicated on edits so that really could save some significant space.Hi, is the project being continued? People hosting sbds have problem with maintaining it, it brakes all the time.
The project is continuing, but I ran into exactly the problems you're describing.
There has been a lot of work on SBDS over the last few months and there is an open issue to deploy an update, which I hope happens soon.
Basically, I'm dead in the water like everyone else until this gets fixed, but once it does I'll be back online!